Bucket tree¶
概述¶
在hyperchain中,账本数据可以分成两部分:
- 区块链数据
- 账户数据
其中,区块链数据包括:区块、交易、回执等数据。这部分也就是我们传统意义上所说的区块链。所有区块被从后向前有序地链接在这个链条里,每一个区块都指向其父区块。
区块中包含了一批交易,由共识模块负责将接收到的交易统一定序并打包成一个区块进行分发。区块链节点在接收到一个区块之后,在原有的状态基础上,依次执行交易,在此期间读/写相关账户的状态数据;执行结束,将期间所有的账本改动统一写入。每一笔交易的执行,都意味着区块链进行了一次状态变迁。
在这里,区块链状态指代的是区块链上所有账户状态的集合,该状态集统称为世界状态。由于支持智能合约,因此与以太坊一样,hyperchain摒弃了比特币的UTXO模型而采用账户模型来组织数据,因而这部分数据称为账户数据。
所以,hyperchain的账本体系可以大致分为上述两部分,架构示意图如下所示。
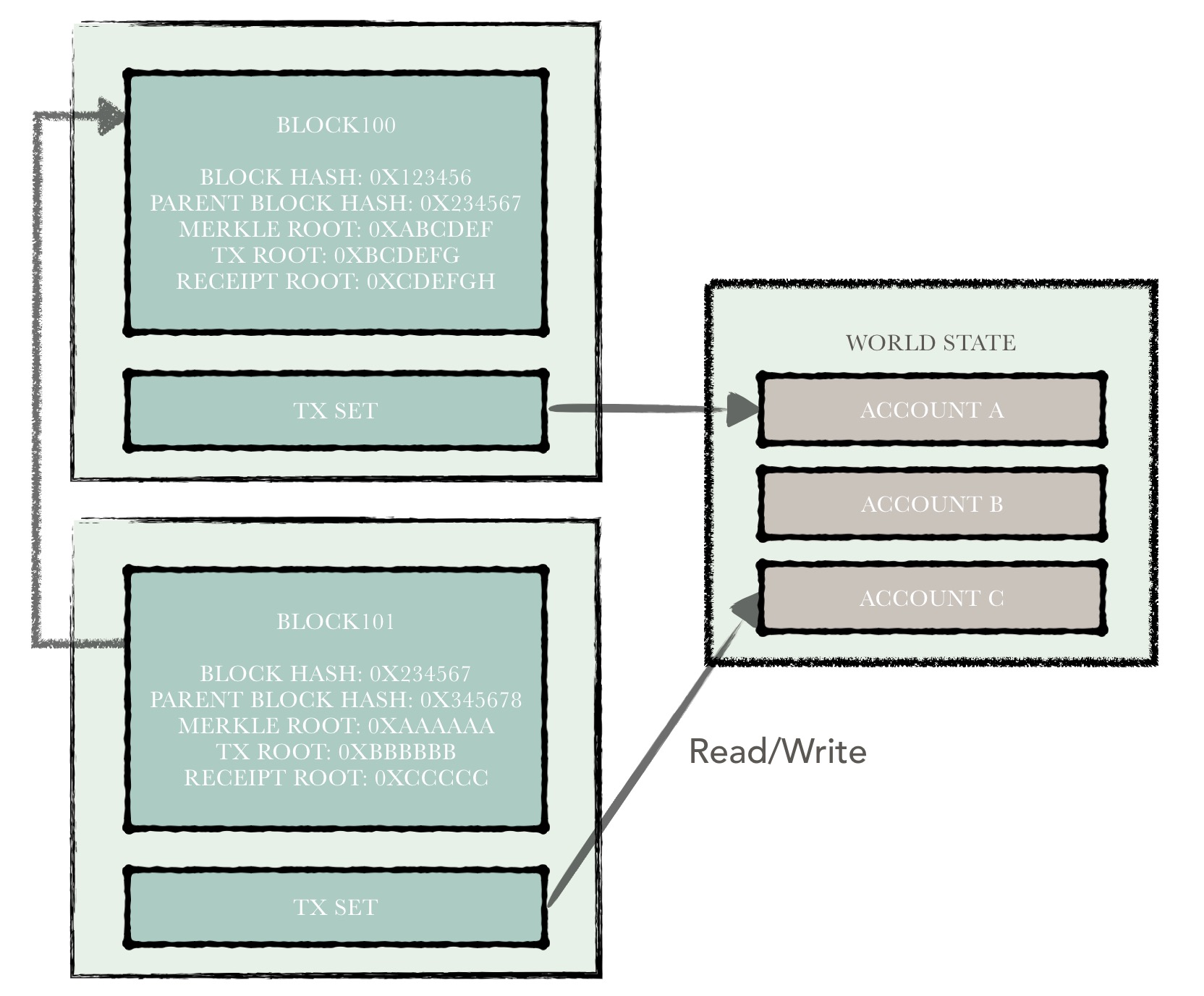
在本文中我们不展开对账本结构的讨论。而来讨论一种用来快速计算账户集状态的树结构 - bucket tree。在hyperchain中,每执行完一个区块,各个节点需要在共识的第三阶段比较执行的结果是否一致。也就是说,每个节点在执行完一个区块后,账户数据需要保持一致。因此,hyperchain中使用了一种bucket tree的结构对账户数据进行哈希计算,节点间只需要通过比较该哈希值就能判断账户数据的一致性。
注解
值得注意的是,bucket tree并不组织和维护账户数据,而仅仅只是进行状态的哈希计算。
bucket tree有以下特点:
- 提供了一种快速计算账户数据哈希标示的机制;
- 提供了账本回滚的机制;
hyperchain中的bucket tree思想最早从fabric项目中借鉴得到,进行了一系列的重构和优化,使得最终的性能表现符合生产需求。下文中,将详细介绍这种树的结构、主要操作以及最终的性能表现。
结构解析¶
bucket tree其实是揉合了两种不同的数据结构组合而成,这两种数据结构为:
- merkle树
- 哈希表
因此在介绍bucket tree的结构之前,我们首先简要地介绍一下上述两种数据结构。
merkle树¶
Merkle树是由计算机科学家 Ralph Merkle 在很多年前提出的,并以他本人的名字来命名,在比特币网络中用到了这种数据结构来进行数据正确性的验证。
在比特币网络中,merkle树被用来归纳一个区块中的所有交易,同时生成整个交易集合的数字指纹。此外,由于merkle树的存在,使得在比特币这种公链的场景下,扩展一种“轻节点”实现简单支付验证变成可能。
特点
- 默克尔树是一种树,大多数是二叉树,也可以多叉树,无论是几叉树,它都具有树结构的所有特点;
- 默克尔树叶子节点的value是数据项的内容,或者是数据项的哈希值;
- 非叶子节点的value根据其孩子节点的信息,进行Hash计算得到的;
原理
在比特币网络中,merkle树是自底向上构建的。在下图的例子中,首先将ENTRY1-ENTRY4四个单元数据哈希化,然后将哈希值存储至相应的叶子节点。这些节点是Hash0-0, Hash0-1, Hash1-0, Hash1-1
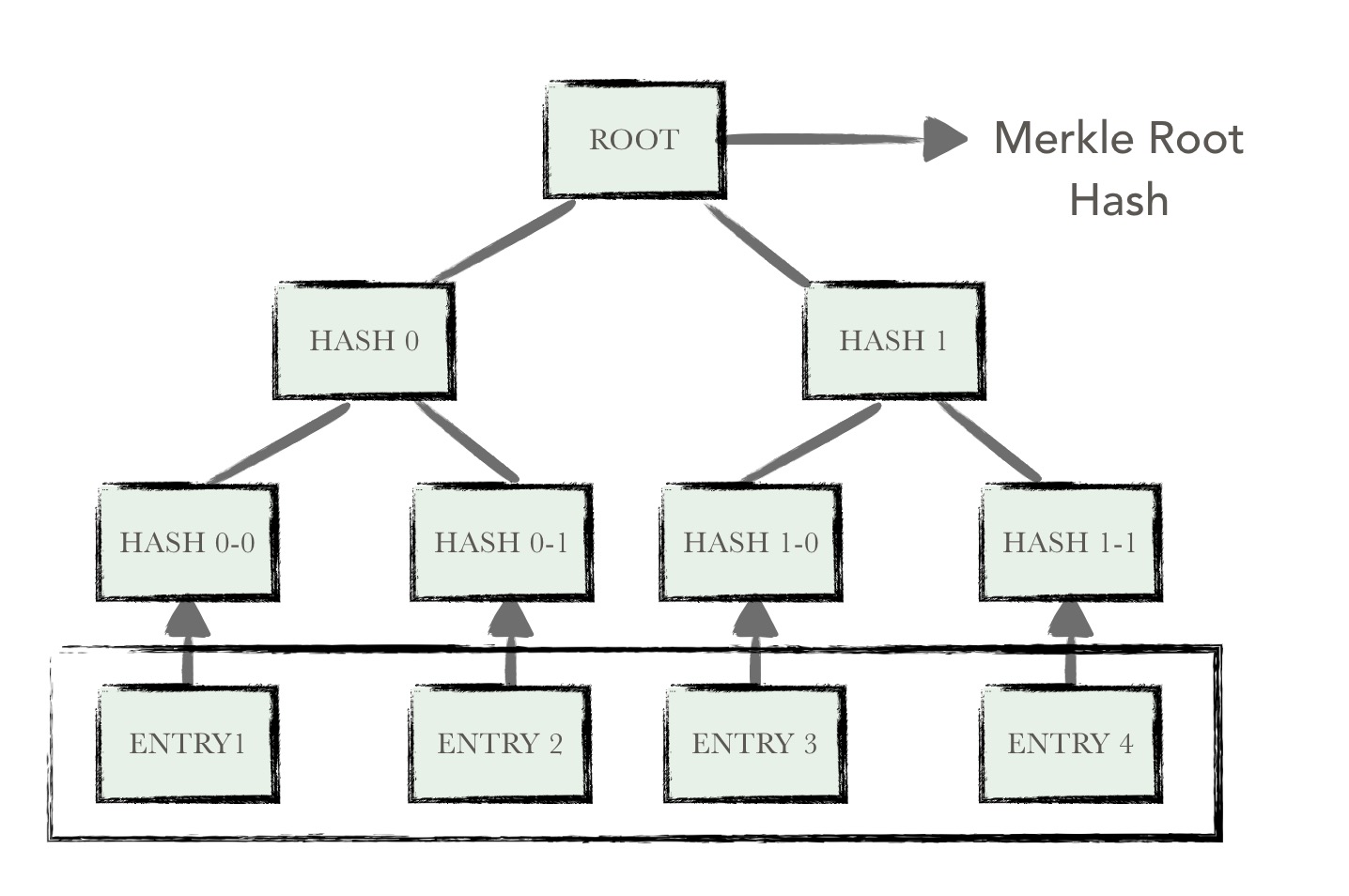
将相邻两个节点的哈希值合并成一个字符串,然后计算这个字符串的哈希,得到的就是这两个节点的父节点的哈希值。
如果该层的树节点个数是单数,那么对于最后剩下的树节点,这种情况就直接对它进行哈希运算,其父节点的哈希就是其哈希值的哈希值(对于单数个叶子节点,有着不同的处理方法,也可以采用复制最后一个叶子节点凑齐偶数个叶子节点的方式)。循环重复上述计算过程,最后计算得到最后一个节点的哈希值,将该节点的哈希值作为整棵树的哈希。
若两棵树的根哈希一致,则这两棵树的结构、节点的内容必然相同。
采用merkle树的优势是:当某一个节点的内容发生变化时,仅需要重新计算从该节点到根节点路径上所有树节点的哈希,即可重新得到一个可以代表整棵树状态的哈希值。也正是因为merkle树的这个特点,使得bucket tree能够避免许多不必要的计算开销,拥有快速计算账户状态哈希的能力。
哈希表¶
哈希表,也称散列表,是大家非常熟悉的数据结构,是根据键(key)而直接访问在内存存储位置的。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数,存放记录的数组称做散列表。
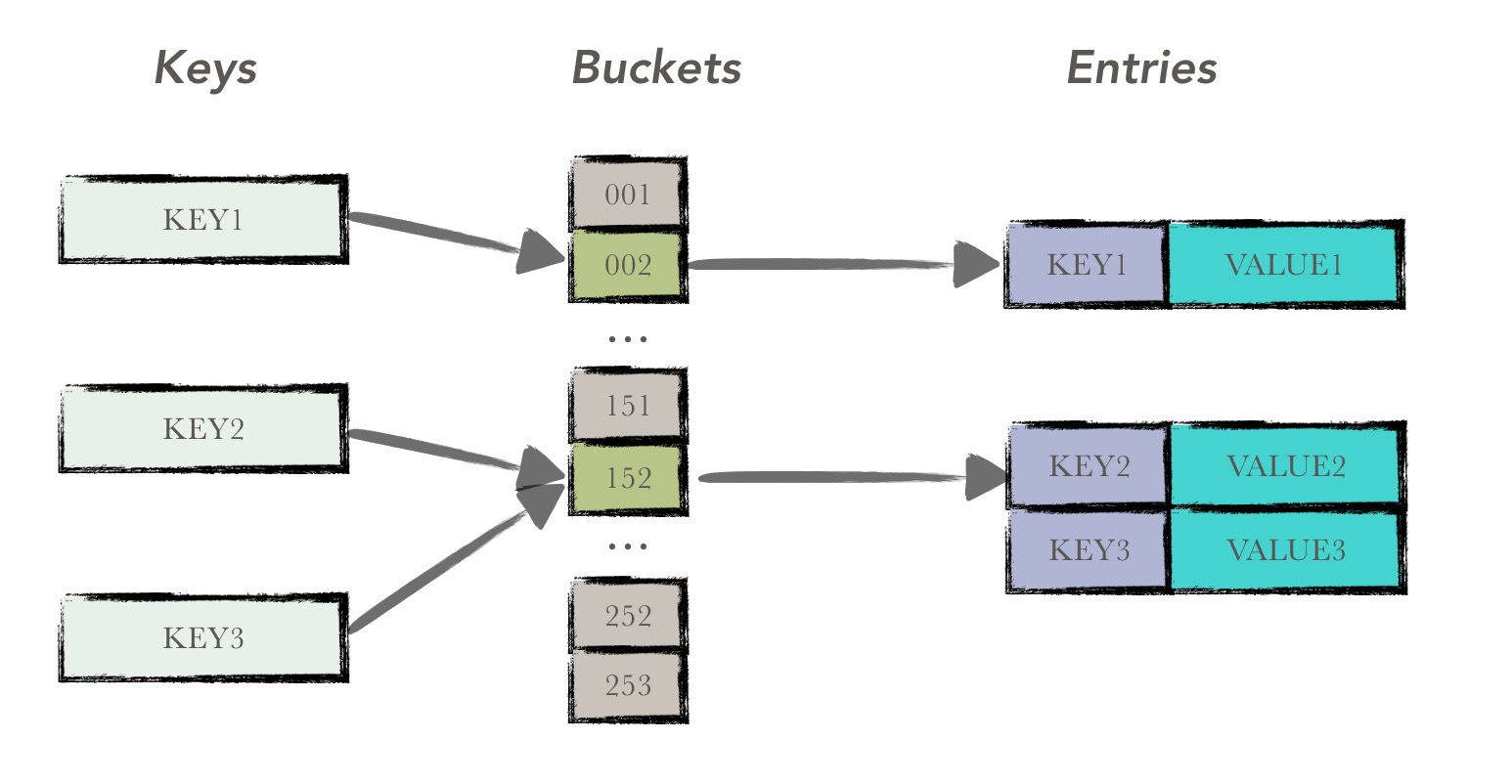
有关于哈希表的描述,在此就不再赘述了。在bucket tree中,使用哈希表来维护原始的数据。
bucket tree¶
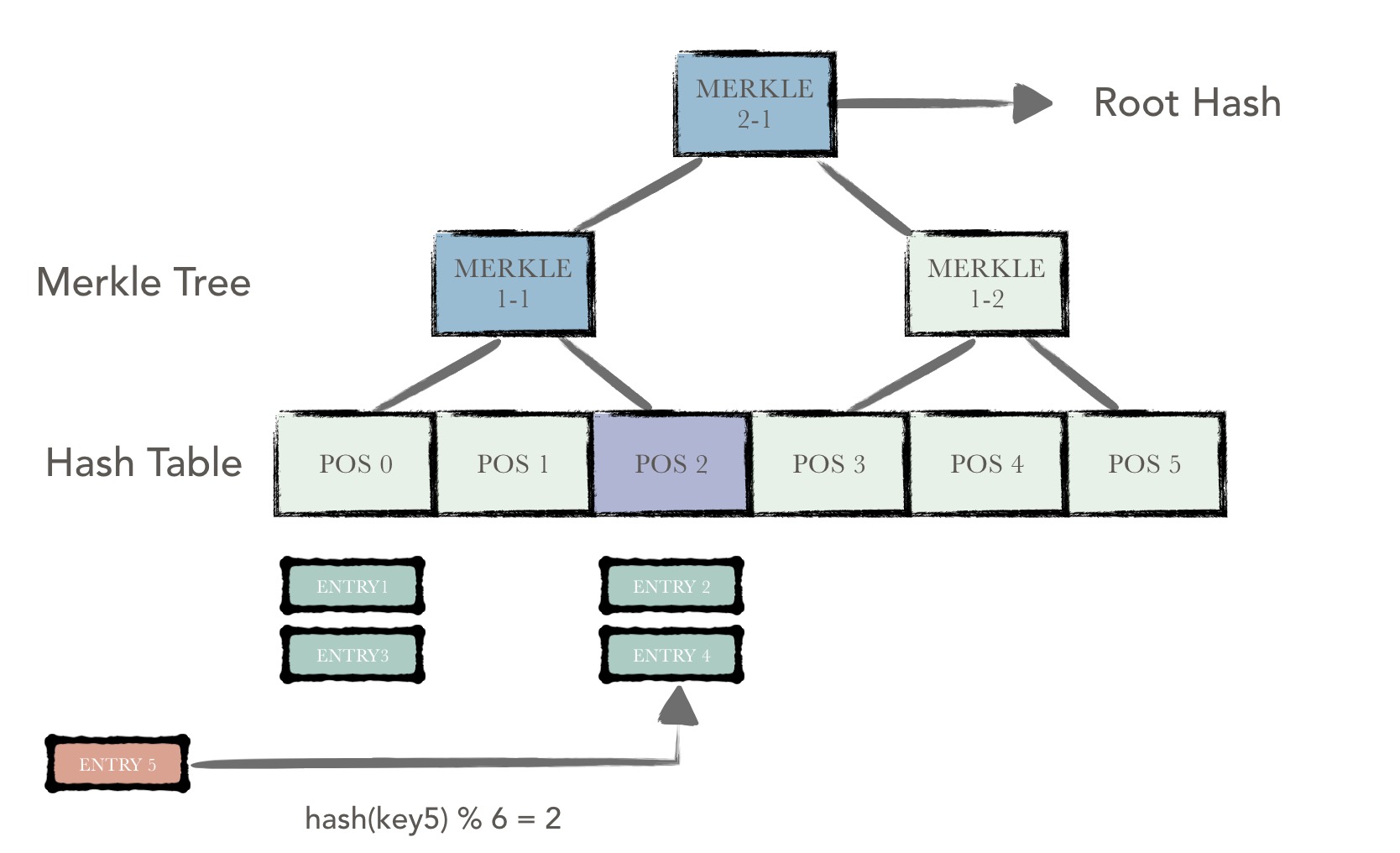
bucket tree由两部分组成:底层的哈希表以及上层的默克尔树。也就是bucket tree其实是一棵建立在哈希表上的默克尔树。
哈希表由一系列哈希桶(bucket)组成,每个桶中存储着若干被散列到该桶中的数据项(entry),所有数据项按序排列。每一个桶有一个哈希值用来表示整个哈希桶的状态,该哈希值是根据桶内所有数据项的内容进行哈希计算得到。
除了底层的哈希表以外,上层是一系列的merkle树节点。一个merkle树节点对应着下一层的n个哈希桶或者merkle树节点。这个n也称作merkle树的聚合度。该merkle树节点中维护着这n个孩子节点的哈希值,且merkle树节点本身的哈希值是根据这n个孩子节点的哈希值计算得到。
如此不断迭代,最终最上层的树节点是整棵树的根节点,该节点的哈希值就代表着整棵树的哈希。
如此设计的目的是:
- 利用merkle树的特点,使得每次树状态改变,重新哈希计算的计算代价最小;
- 利用哈希表进行底层数据的维护,使得数据项均匀分布;
例如上图中,一条新的数据项entry5插入,该数据项被散列到POS为2的桶中。该桶,即从该桶至根节点上所有的节点被标为粉红色,即为脏节点。仅对这些脏节点进行哈希重计算,便可得到一个新的哈希值用来代表新的树状态。
由于bucket tree是一棵固定大小的树(即底层的哈希表容量在树初始化之后,就无法更改了),随着数据量的增大,采用散列函数将所有的数据项进行均匀散列可以避免数据聚集的情况发生。
此外,bucket tree有两个重要的可调参数:
- capacity
- aggreation
前者表示哈希表的容量,该值越大,整棵树相对来说能够容纳的数据项的个数就越多,在聚合度不变的前提下,树高越高,从叶子节点到根节点路径上的树节点个数也越多,哈希计算次数增加;
后者表示一个父节点对应的孩子节点的个数,该值越大,表示树的收敛速度越快,在哈希表容量不变的前提下,树高更低,从叶子节点到根节点路径上的树节点个数也越少,哈希计算次数减少;但是每个默克尔树节点的size就越大,增加数据库IO开销;
哈希桶¶
哈希桶的定义如下,由一系列的数据项组成,注意这些数据项是按key的字典序排序的,每一个数据项即代表了一条用户数据(可以优化为仅存储用户数据的哈希值)。
type Bucket []*DataEntry
merkle节点¶
merkle节点的定义如下,主要的字段为与其相关的孩子节点列表,该列表中的每一个元素都是一个孩子节点的哈希值。
// MerkleNode merkleNode represents a tree node except the lowest level's hash bucket.
// Each node contains a list of children's hash. It's hash is derived from children's content.
// If the aggreation is larger(children number is increased), the size of a merkle node will increase too.
type MerkleNode struct {
pos *Position
children [][]byte
dirty []bool
deleted bool
lock sync.RWMutex
log *logging.Logger
}
核心操作¶
bucket tree的计算过程可以分为以下四阶段:
- Initialize
- Prepare
- Process
- Commit
Initialize¶
在初始化阶段,主要进行构建树形态的构建,cache的初始化以及历史数据的恢复(从db中读取最新的根节点的哈希)
所谓树形态的构建就是利用用户配置的capacity及aggreation两个参数构建树的结构。构建函数如下:
var (
curlevel int
curSize int = cap
levelInfo = make(map[int]int)
)
levelInfo[curlevel] = curSize
for curSize > 1 {
parSize := curSize / aggr // 根据收敛系数计算下一层的节点个数
if curSize%aggr != 0 {
parSize++
}
curSize = parSize
curlevel++
levelInfo[curlevel] = curSize
}
conf.lowest = curlevel
for k, v := range levelInfo {
conf.levelInfo[conf.lowest-k] = v // 将每一层的节点个数信息倒置,使得根节点处于0层,哈希桶处于最高层
}
此外,bucket tree为了(1)增加读取的效率(2)防止写丢失,增加了两个cache用于缓存哈希桶和merkle节点的数据。这两个cache都是利用LRUCache实现的,每次更新时都会同步地更新cache中的内容。如此,下一次bucket tree进行哈希计算时,便可以从cache中命中热数据,尽量避免磁盘的读取。
至于防止写丢失是因为在hyperchain中,validation和commit是两个独立异步的过程,因此在进行完区块100的validation过程时,可能会立刻基于100的状态直接进行区块101的validation。而此时区块100执行过程中对账本的修改还没有被提交的数据库中,因此为了“防止写丢失”,这些内容需要从缓存中命中。
倘若此刻cache发生了容量过小未提交的内容被驱除的情况,就会导致区块101的validation的结果与其他节点不一致(通常为主节点),此时会依赖于RBFT算法进行故障处理。
其中bucketcache是用来存储哈希桶的数据,每一个哈希桶为一个cache数据项。存在的问题是,一个哈希桶本身由若干条数据项组成,随着运行时间增长,一个哈希桶的size会越来越大,导致内存占用量不断上升。
merkleNodeCache是用来存储除最高层以外的所有merkle节点数据的,merkle节点个数是固定的,每个节点的size也是有上限的,因此merkleNodeCache不存在内容占用量变大的问题。
Prepare¶
在准备阶段,bucket tree会接收由用户传入的修改集,并利用修改集的内容构建脏的哈希桶集。注意,返回的哈希桶中,内部的数据项是按字典序升序排列的。
func newBuckets(prefix string, entries Entries) *Buckets {
buckets := &Buckets{make(map[Position]Bucket)}
for key, value := range entries {
buckets.add(prefix, key, value)
}
for _, bucket := range buckets.data {
sort.Sort(bucket)
}
return buckets
}
Process¶
process也就是哈希重计算阶段,可以分为两部分(1)脏哈希桶的哈希重计算(2)脏merkle节点的哈希重计算。
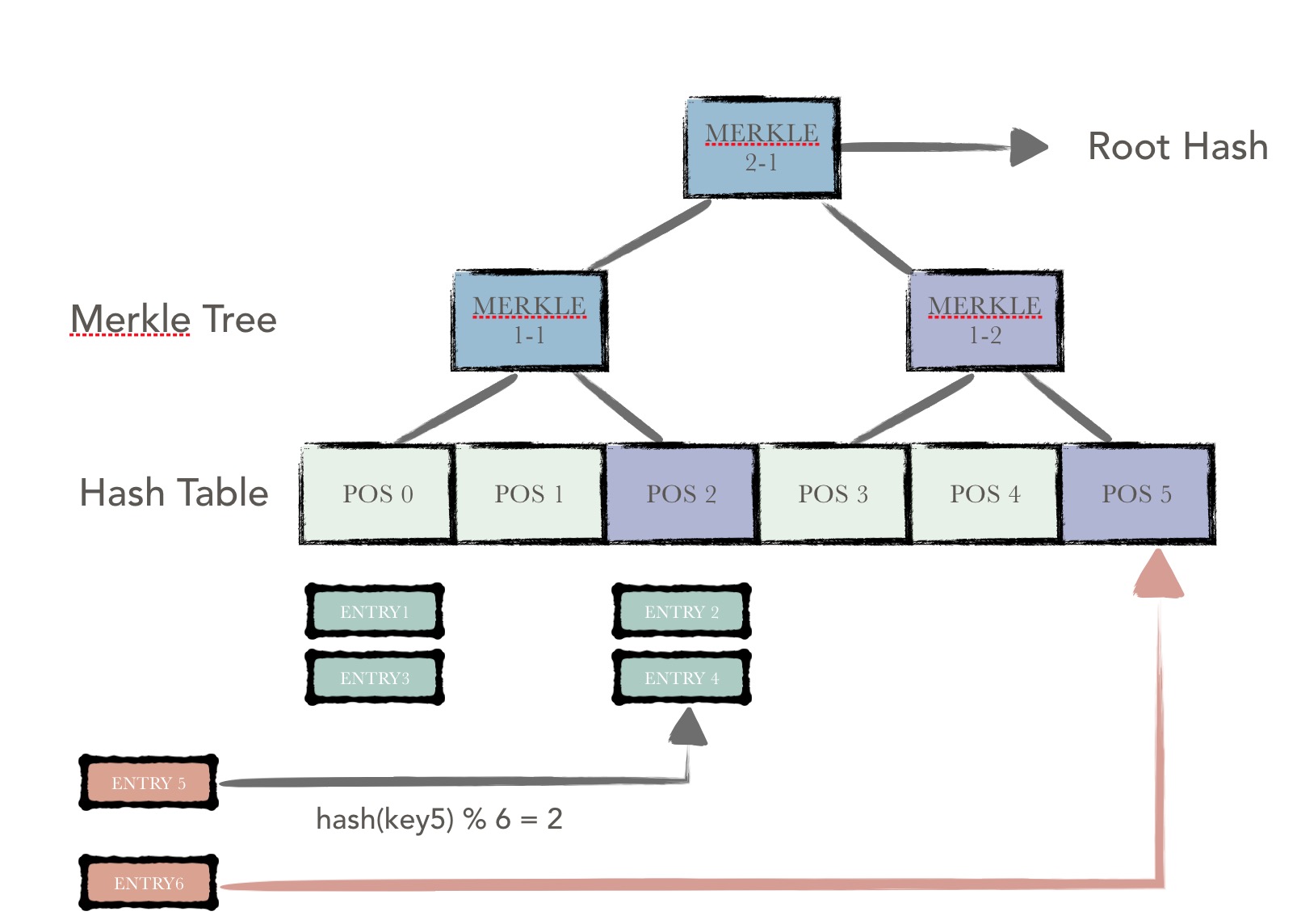
脏哈希桶计算
如上图所示,在bucket tree中新插入两条数据项entry5, entry6。entry5得到的散列地址为Pos2,entry6得到的散列地址为Pos5。
哈希桶计算存在一个合并的操作,即在Pos2,需要将新插入的数据,与历史的数据进行一个合并,且按照固定的排序算法进行重排序,最终得到一个新的哈希桶,包含了所有的新旧数据,且按序排列。
每个哈希桶的哈希值为当前桶中数据的进行哈希计算得到的结果。
如图所示,Pos2与Pos5为两个脏的哈希桶,计算完成之后,将父节点中对应的孩子哈希值置为新的桶哈希值,即Merkle1-1,Merkle1-2为两个脏的merkle节点。
脏merkle节点计算
当哈希桶计算完成之后,便可以进行merkle节点的哈希计算。这步中仅对脏的merkle节点进行哈希重计算。
注意,merkle节点的哈希计算是分层进行的。
每个merkle节点维护其孩子节点的哈希值,若下一层的孩子节点哈希值发生变化,会在之前的计算中,就将最新的哈希值置到父节点中;对于没有发生变化的孩子节点,直接使用历史的哈希值即可。
每个merkle节点的哈希值,为其所有孩子节点哈希值的哈希计算得到。
Commit¶
计算完成之后,需要将最新的哈希桶数据、merkle节点数据进行持久化。
除此以外,所有的哈希桶数据、merkle节点数据都会被存储到缓存中,对于热数据,既可以提高数据的查找效率,也可以避免数据的写丢失情况。